

When Domain-Specific Models Win
Summary
- There’s a tradeoff between generality and efficiency: general models cover more domains but are more expensive to train as a result of being larger, needing more data to train, and being architecturally geared to natural language processing. Domain-specific models have less breadth but are more efficient to train as a consequence of being smaller, needing less data, and being architecturally optimized.
- Opportunities for domain-specific models to be competitive arise when reasoning is sufficiently idiosyncratic to that domain. Here domain-specific models can overcome the scale economies and convenience for users that general models have.
- Domain-specific models can compete along two axes: cost of inference or quality of inference. Both can produce winners, but competing on quality is arguably the larger opportunity because progress in many domains is bottlenecked by capability, not willingness to pay.
- For quality-focused domain-specific labs, verifier accessibility is the primary determinant of defensibility. When verifiers are openly available, advantages compound only as fast as the lab can out-discover competitors. Leads exist but are fragile. When verifiers are expensive or proprietary (requiring wet labs, custom hardware, regulatory access, or deep institutional partnerships), the resulting data is genuinely proprietary and compounds defensibly over time.
Introduction
Harmonic’s Aristotle scored 71% on ProofBench — 15% ahead of GPT-5.4 and 17% ahead of Claude’s Opus 4.7. Aristotle is not a frontier model in the usual sense. It runs on a fraction of the compute budget, targets a narrow domain, and comes from a team a fraction of the size. But in the specific domain of formal mathematical proof generation, it vastly outperforms.
In recent months, there’s been an outpouring of domain-specific AI labs raising significant funding. We’ve seen labs for physics (PSI, Periodic), drug discovery (Isomorphic, Chai), robotics (PI, Skild), math (Math Inc., Harmonic), and others.
These are signals worth taking seriously. The outperformance in commercially valuable domains combined with investors pouring money into domain-specific model companies indicates that perhaps the monolithic path to superintelligence is not the only credible way forward. Despite frontier LLM labs being better resourced and casting a wide net across many industries, there are early signals that domain-specific models can win big in their own respective verticals. The question for investors, users, and builders is where this pattern of specificity-as-advantage holds, and where it doesn’t.
Generality vs. Efficiency
A starting point for this analysis is to examine the tradeoff between generality and efficiency. General models have the largest TAM. Their reasoning is tailored towards tackling as many knowledge-work tasks as possible. This TAM is a big reason why frontier labs building general models are able to raise significant amounts of capital to pour into compute to scale their models’ quality and distribution.
But the breadth comes at a cost. General models carry enormous parameter counts, which are necessary for covering many domains. They require training on dozens of TBs of natural language data. They are tokenized for natural language rather than for domain-specific building blocks like mathematical statements or molecular structures. And their gradients during post-training can dilute across every task the model has to serve.
Domain-specific models, by contrast, are smaller and trained on less data, and their architectures are optimized with the logical structure of the specific domain in mind. As a consequence, they tend to be cheaper to train and yet perform on par with (or even outperform) general models in their respective domains. At a high level, this is the efficiency tradeoff that allows domain-specific models to deliver better performance per dollar of compute.
This tradeoff produces two archetypes of winners.
The first archetype wins when reasoning is sufficiently generalizable across many domains or subdomains — such as different forms of writing where summarizing, argumentation, email drafting, etc. all require similar skills. In these scenarios, general reasoning models typically win on convenience and quality. Their quality is on par with or higher than domain-specific models as a consequence of the scale economies in training that frontier labs can amass, cross-pollination of skills, and the network effects from building up context on users’ preferences. And they are also convenient as they can tackle a number of related tasks in one place, creating stickiness and lock-in as users build familiarity with the interface.
The second archetype presents itself in domains where reasoning is sufficiently idiosyncratic. In these scenarios, domain-specific models have an opportunity to win. This archetype can be broken down even further. To date, there are two paths to winning for domain-specific models:
- Compete on the cost of inference
- Compete on quality of inference
As is the case across any business, the extent to which a moat can be established is the extent to which it can persistently outperform, whether on cost or quality. In the following sections, I explore examples of domain-specific model companies in both categories — cost and quality. What we find is that both develop their moat from proprietary data and verifiers. But in some cases the corresponding moat and/or opportunity for domain-specific models is much larger.
The Moat for Domain-Specific Models
Unlike general reasoning models, the primary moat for domain-specific models is not scale economies. Domain-specific models are cheaper to train than their general counterparts. Data is scarcer and the models are smaller. As a consequence of this and a rabid appetite to fund from VCs, money and amortization are not the constraint.
Instead, the constraints are proprietary data and verifiers. In domains where data is scarce, the marginal data your competitor doesn’t have means a whole lot more. And access to scarce verification systems unlocks high quality, structured data your competitors can’t acquire.
What matters in this lens is how difficult it is to replicate the data and verification process needed to improve the model. Some domains have expensive verification processes that require expansive distribution, custom hardware, wet labs, regulatory licenses, or deep know-how. And in others, verifiers are openly available to all. So as different domains vary in these factors, so do the moats of companies building within these domains, and, as a result, so does their ability to sustain an advantage on quality.
Why Verification Matters
The ability to verify the quality of an output is what transforms an output from plausibly useful into being useful in a way that’s closer to ground truth. In domains where a verifier exists — a formal proof checker like Lean, a unit test suite for code — a model can generate large volumes of candidate outputs and automatically determine which ones are correct. This creates a self-improving flywheel known as a Reinforcement Learning with Verifiable Rewards (RLVR) loop: verified outputs can become new training data, which improves the model’s ability to generate more correct outputs, which yields more training data. In environments where a verifier exists naturally, recursive improvement is more streamlined than incentivizing third-party human labelers.
In this post, we also extend “verification” to encompass processes that generate human feedback. An example of this would be an IDE that tracks what changes are accepted, rejected, or edited in real coding workflows. A further distinction could be made that contrasts direct incentives to human labelers against verification that occurs as a residual of an existing service. In the latter scenario, capital is not the direct constraint. Distribution is. When scalable distribution exists (as it does in the case of Cursor), we see that “verification” can be similarly scalable and streamlined as it is when a non-human ground truth verifier exists.
To summarize, without a great verifier, you’re stuck with hard-to-scale proxies that might not reflect true correctness. Having ground truth verifiers or human feedback integrated through real workflows is ideal.
What Makes Verification Difficult?
In the examples we’ll explore, there are two determinants of verification difficulty.
The first is how expensive it is to acquire a verifier. For some domains, like math, code, and trading, verifiers are entirely software (oftentimes open source) making them incredibly cheap to acquire. For other domains, like weather and clinical diagnosis, verification requires access to commercially available, specialized hardware. Acquiring and situating verifiers in these circumstances will be more expensive than pure software verifiers. In the most expensive cases, like drug discovery and some problems in materials science, verification requires custom hardware and deep physical process know-how, making it prohibitively expensive for challengers to access verifiers without some combination of lots of capital, deep expertise, and access to institutional partnerships.
The second determinant of difficulty is whether distribution is necessary for verification at scale. This is relevant in areas such as coding, where verification is cheap to run — unit tests and change acceptances or rejections — but having an existing distribution network really helps. IDEs and tools with tons of users can collect unique data to train their models on and give a model a leg up. A similar dynamic is present in self-driving cars; Waymo and Tesla have extended their lead in part because they are more operationalized than other competitors.
Now let’s explore examples of competing on cost and quality to determine where the most defensible and ambitious opportunities may live.
Competing on Cost
A canonical example of domain-specific models competing primarily on cost of inference is Cursor’s Composer 2 (a coding model). Composer 2 scored slightly ahead of Opus 4.6 on CursorBench and Terminal-Bench 2.0 and slightly behind GPT-5.4 on both. More importantly, it serves that performance at one-tenth of Opus’ price and one-fifth of GPT-5.4’s on input. Cursor’s Composer 2 model could pull this off because of a proprietary data advantage, compounded over years of IDE telemetry and human feedback on real coding workflows. Concretely, this is data on which suggestions developers tend to accept, which ones they reject, and which edits they make afterward. Composer 2 is built on Moonshot AI’s open-source Kimi K2.5, with Cursor layering continued pre-training on its code corpus plus RL against long-horizon agentic tasks on top. In these cases, the foundation model is cheap to acquire, and the moat becomes the proprietary data used in fine-tuning. Cursor’s advantage with Composer 2 is not that it’s better than a frontier model at coding — only that it can be just as smart at a lower cost.
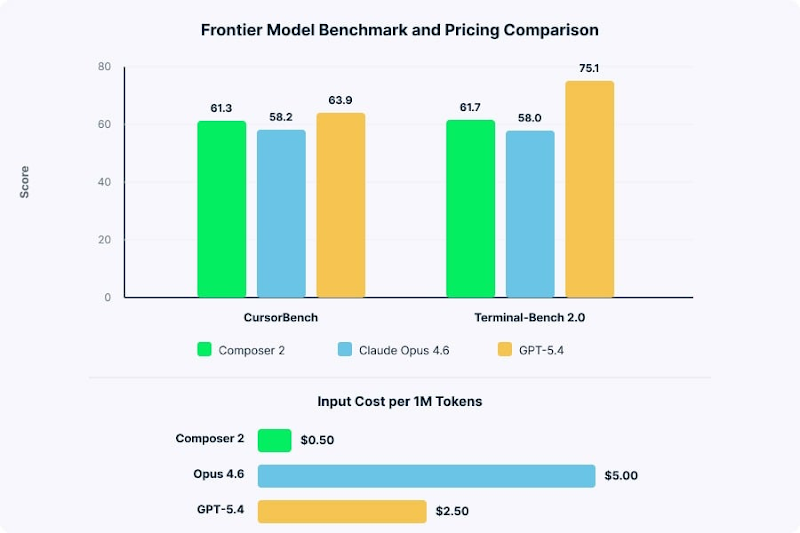
In my opinion, competing on cost alone is the less attractive business model. While Cursor’s IDE product is wildly successful, there isn’t widespread excitement from developers over Composer 2 specifically. Saving money is nothing to write home about. As evidence, just look at the reception of Claude Code. Despite being more expensive, it’s been able to garner significant attention and adoption.
Now contrast that with competing on quality.
Competing on Quality
Competing on quality is a much larger and more meaningful opportunity than competing on cost. Discovering new knowledge and technology can be invaluable. Just ask yourself what a cancer cure or commercially viable fusion reactor would be worth. In these cases, our ability to generate new knowledge and technology is not bottlenecked by willingness to spend, but by our current understanding and technical capabilities. And models that compete on quality are naturally better suited to advancing our tool kit.
But to understand where advantages will be sustained (and where value will accrue) in domain-specific models capable of scientific discovery, we have to revisit a previous prompt: Where is verification accessible, and where is it not?
Accessible Verifiers
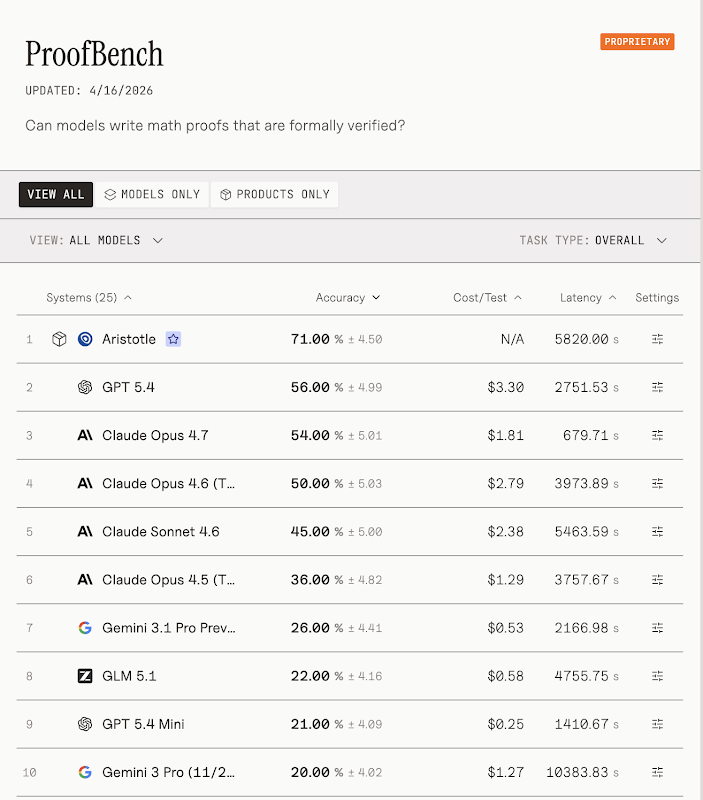
On one end of the spectrum, you have labs such as Harmonic (a math model) competing on quality. Their pitch is not that they serve frontier-level output cheaper, but that they produce superior performance. And the preliminary numbers back it up: Harmonic’s Aristotle leads ProofBench by 15 points over the nearest general reasoning competitor (GPT 5.4).
Notably, Aristotle is not a monolithic model, but rather a system with three sub-models:
- An informal reasoning system, which is trained on and outputs proof sketches in natural language
- A formal reasoning system, which takes the informal reasoning system’s output as input and iterates on formalizing proofs in Lean
- A geometry solver that’s optimized for finding and verifying geometry proofs
Each sub-model serves a purpose. The informal reasoning system helps inform the two formal reasoning systems on what directions to pursue. And the two formal reasoning systems translate that direction into something that can be formally verified. The choice to break the formal reasoning system down into two separate sub-models is also informative. Lean, the verifier most commonly used, is particularly inefficient when it comes to specifying and verifying geometry proofs. This alludes to why domain-specific models can outperform in certain cases — the logical structure of a geometry proof is sufficiently idiosyncratic to where there are meaningful performance gains in optimizing the architecture around these idiosyncrasies.
In terms of moat, Aristotle’s data advantage is even subtler than what we previously saw with Cursor. When Aristotle discovers new proofs that are then formally verified, it can use those proofs and reasoning traces as additional training data. This unlocks recursive self-improvement, where each verified proof can in turn be used to improve the model in future use. Notably, this is not a proprietary data moat, but rather one built around the speed of discovering new data. All labs have access to proof verifiers such as Lean and Coq, and math proofs are not particularly proprietary — you can’t patent a mathematical proof alone. This means that competitors could still self-improve on the same verifiable outputs if they independently discovered them. As a consequence, Aristotle’s performance edge only helps it generate new training data faster than competitors, allowing it to extend its lead only so long as it outperforms those competitors in discovering new proofs.
Inaccessible Verifiers
But in other domains, verifiers are difficult to construct and unavailable to competitors. As a consequence, the data they help generate can be proprietary and compound model quality in a defensible manner.
Consider Isomorphic Labs’ IsoDDE (short for Isomorphic Labs Drug Discovery Engine), an AI system for assisting with complex tasks in drug discovery workflows. Isomorphic Labs, and the systems it builds, compete squarely on developing models that outperform on the quality of inference. The team spun out of Google DeepMind’s AlphaFold team, and contributed to AlphaFold 3 under the Isomorphic Labs entity. Notably, unlike any of the AlphaFold models, IsoDDE’s weights are fully proprietary.
Reinforcement learning with verifiable rewards requires that the model has access to verifiers that can accurately report on “ground truth.” In the context of mathematics, it’s trivial to access high quality, ground truth verifiers, such as Lean and Coq, which are openly available for use by AI labs. But for many other domains, verifiers are not as easy to come by.
Unlike math, in drug discovery, there is no publicly available and digital Lean-equivalent for checking an output against ground truth. There are tools that can help, such as the open Protein Data Bank, which has ~230,000 experimentally determined protein structures and other imperfect physics-based verifiers. But there is no perfect digital substitute for the slow and proprietary process of wet-lab feedback for new drug discoveries.
To date, Isomorphic Labs has inked partnerships with Johnson & Johnson, Novartis, and Eli Lilly, three of the largest drug manufacturers globally, which are collectively worth over a trillion USD. While the details of the Johnson & Johnson partnership are undisclosed, it is known that the Novartis and Eli Lilly deals involve an eight-figure base payout for the engagement, over $1B in milestone payments as earn-outs, as well as a meaningful share of future royalties (up to low single-digit percentages) for Isomorphic Labs on any sales.
Of particular interest to this piece are the royalties. A meaningful share of royalties between the two parties aligns incentives with the success of the drug compounds produced via IP sharing — encouraging collaboration and a reasonable basis to expect deeper IP sharing in the form of wet-lab data. To be clear: the publicly available details make no explicit mention of sharing wet-lab data. However, a royalty structure that ties Isomorphic Labs’ returns directly to the commercial success of specific compounds creates a stronger incentive for such drug manufacturers to share proprietary experimental data and signals a willingness to share IP Isomorphic Labs is instrumental in developing. It’s reasonable to expect that data access follows.
Drug manufacturers are only required to report data on later phases of clinical trials. Everything before the later stages of clinical trials, however, can remain private. This includes valuable experimental data on the structure of how drug candidates bind to target proteins, how cleanly they discriminate between the intended target and non-target proteins, how the body absorbs and processes them, what doses cause toxicity in animals, and, critically, which compounds were abandoned and why. Incumbents like Novartis, J&J, and Eli Lilly have accumulated this proprietary data over decades. And, importantly, for Isomorphic Labs’ moat, no public database captures it. It’s also reasonable to expect that the pace at which such data is generated will only be accelerated via deep integration with IsoDDE, granting Isomorphic Labs a compounding and proprietary head start.
And unlike math theorems, drug compounds can be patented. US and international patent laws grant exclusivity to the first synthesis of a new chemical. This strengthens the first-mover advantage for the party that discovers a compound first as they can exclusively capture the financial upside of their discoveries.
Conclusion
We started with the premise that there’s a tradeoff between generality and efficiency: general models cover more domains but are more expensive to train as a consequence of being larger, needing more data to train, and being architecturally geared to natural language processing. In contrast, domain-specific models have less breadth but are more efficient to train as a consequence of being smaller, needing less data, and being architecturally optimized.
From there, the opportunities for domain-specific models to be competitive arise when reasoning is sufficiently idiosyncratic to that domain. In these settings, domain-specific models can overcome the advantages of general reasoning models — scale economies and convenience for users — by providing superior cost or quality.
Both the cost and quality angle can produce winners. And for both, the moat is downstream of an ability to access new training data before competitors. But competing on quality is arguably the larger opportunity. New knowledge and technology can be invaluable, and it’s bottlenecked by capability, not willingness to pay.
For all domain-specific models, verifier accessibility is the primary determinant of defensibility. When verifiers are openly available, advantages compound only as fast as the lab can out-discover competitors. Leads exist but are fragile. But when verifiers are difficult to access (requiring wet labs, regulatory licenses, expensive and custom technology, existing distribution, or deep institutional partnerships), the resulting data can be genuinely proprietary and compound defensibly.
Expect value to accrue here, to the models that are capable of accelerating the discovery of new knowledge in domains where verification is hard to come by.
Disclaimer
All information contained herein is for general information purposes only. It does not constitute investment advice or a recommendation or solicitation to buy or sell any investment and should not be used in the evaluation of the merits of making any investment decision. It should not be relied upon for accounting, legal or tax advice or investment recommendations. You should consult your own advisers as to legal, business, tax, and other related matters concerning any investment. None of the opinions or positions provided herein are intended to be treated as legal advice or to create an attorney-client relationship. Certain information contained in here has been obtained from third-party sources, including from portfolio companies of funds managed by Variant. While taken from sources believed to be reliable, Variant has not independently verified such information. Any investments or portfolio companies mentioned, referred to, or described are not representative of all investments in vehicles managed by Variant, and there can be no assurance that the investments will be profitable or that other investments made in the future will have similar characteristics or results. A list of investments made by funds managed by Variant (excluding investments for which the issuer has not provided permission for Variant to disclose publicly as well as unannounced investments in publicly traded digital assets) is available at https://variant.fund/portfolio. Variant makes no representations about the enduring accuracy of the information or its appropriateness for a given situation. This post reflects the current opinions of the authors and is not made on behalf of Variant or its Clients and does not necessarily reflect the opinions of Variant, its General Partners, its affiliates, advisors or individuals associated with Variant. The opinions reflected herein are subject to change without being updated. All liability with respect to actions taken or not taken based on the contents of the information contained herein are hereby expressly disclaimed. The content of this post is provided “as is;” no representations are made that the content is error-free.